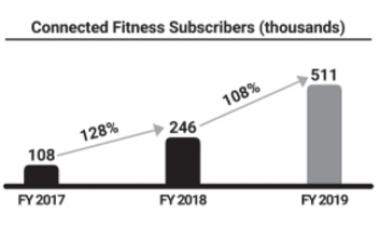
2019年4月11日
作者:迪克·詹姆斯,崔正东
去年的周日晚上,TechInsights在IEDM举行了一次招待会,Arabinda Das和Jeongdong Choe在招待会上做了演讲,吸引了一屋子的与会者。Arabinda是第一个来的,在10年苹果iPhone和半导体技术创新之旅,接着是郑东的讨论。记忆过程、设计和架构:今天和明天”.
Arabinda粗略地回顾了iPhone及其功能部件的发展过程——我们往往会忘记第一代iPhone没有摄像头、指纹传感器、面部识别等功能,所以这绝对是一次回忆之行。
Jeongdong介绍了逆向工程专家看到的最新内存技术,总结了最近的分析,以公平的细节,我想在这篇文章中经历。raybet炉石传说河东是该公司的高级技术研究员,以及他们的记忆技术主题专家。在加入TechInsights之前,他担任SK Hynix和三星推进下一代存储器设备的研发团队领先,所以他知道他说话的地方。
NAND闪存技术

我们先看一看NAND闪存截至2018年11月,前六大制造商的市场份额分别为三星36%、东芝19%、西部数据(WD) 15%、美光13%、SK海力士11%和英特尔6%。
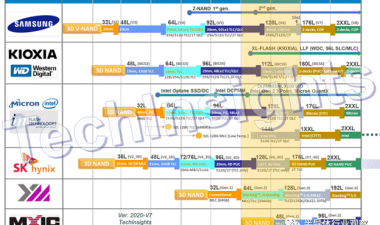
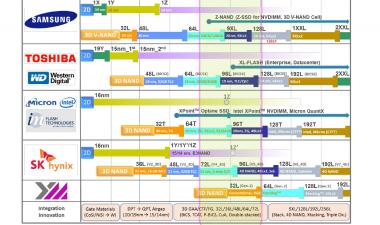
正东公司每年都会制作内存路线图,以下是NAND闪存的最新路线图。你可以看到,我们现在进入了1z-nm平面闪光的时代(可能是13-14 nm,因为1y是~15 nm)~96层3D闪光,有四级细胞。路线图是基于已发布的预测,但我很难相信在短短3年内我们就能达到200多个层次。
图的底部是过去几年的技术发展,从平面器件中的控制栅极从硅化物过渡到钨;然后我们从双图案过渡到四图案,当我们的特征尺寸小于20 nm时。我们看到气隙的广泛采用(事实上,Micron是在25纳米一代开始生产的),随着15/16纳米平面零件的全面生产,3D/V-NAND产品也随之推出。这些产品使用了两种存储技术,电荷阱(将电荷存储在氮化硅层上——三星、东芝/WD和SK Hynix)和浮栅(Micron/Intel)。
9X层3D NAND分析-了解更多
下载我们的3D NAND分析概述,完整的市场概述,NAND技术路线图,模具图像,以及我们可以应用于这些产品的不同分析方法的大纲。

美光/英特尔也使用了不同的布局哲学,提供了更大的区域数据密度;他们设计的堆栈有驱动电路在阵列下,节省外围区域,并使模具更小-他们称为cmos阵列(CuA)。他们的64层产品是2x 32层堆栈,96层产品使用2x 48层堆栈。
展望未来,路线图显示多达256层,平面将淡出除了利基应用。“4D NAND”似乎是SK海力士版的CuA, Xtacking是YMTC(扬子存储技术公司)工艺,在阵列上堆叠CMOS以节省面积。
跟踪平面设备,我们从主要制造商处获得以下序列:

到目前为止,最小的半间距是三星的14nm 128gb芯片,块尺寸为152个电池:

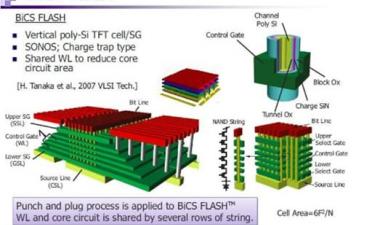
3d nand: 64l & 72l (256 gb & 512gb)
切换到3D-NAND,Jeongdong向我们展示了最近64层和72层设备的总结:

我们可以看到,CuA在英特尔部分是如何将阵列效率提高到近90%的,给出了256gb组中最小的die。iPhone XS Max的SK海力士512 gb内存几乎与256gb内存相同,这是一个令人印象深刻的改进。
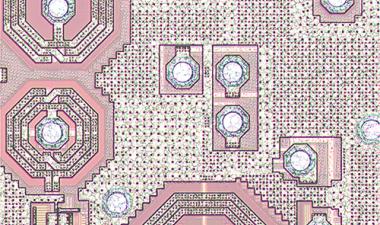
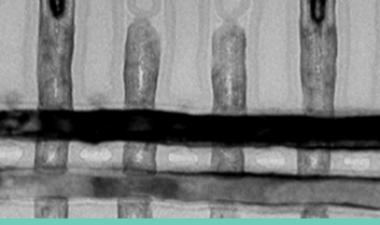
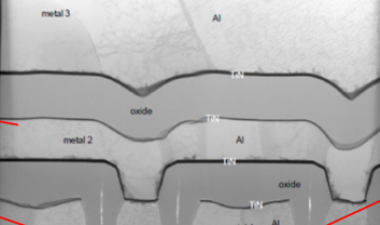
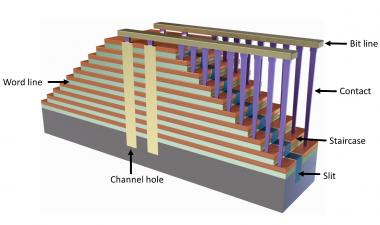
在从48层向64层技术过渡的过程中所取得的进展之一是刻蚀用于在3D-NAND设备中接触字线的“楼梯”。例如,在东芝/WD部件中,由于蚀刻工艺的改进和修整掩模的变化,楼梯的宽度缩小了45%。

这并非无关紧要,即使在收缩之后,楼梯也占据了模具面积的0.82%。同样,三星实现了27%的宽度缩减,楼梯面积减少了0.44%。

英特尔3D FG NAND QLC(64L):第一款3D QLC!
我们还有机会比较了Intel/Micron的三级和四级单元部件;尽管它们都是20 nm,都是64级,但位密度从4.4 Gb/mm2增加到了6.5 Gb/mm2,几乎增加了50%。我们现在处于太比特芯片的时代,Micron刚刚发布了内置8个1 TB芯片的1 TB微型SD卡!

在上面的幻灯片中,晶体管级模具的照片很小,但它们确实缩小得很好:

SK hynix 72L P-BiCS
在这些照片中,我们可以清楚地看到阵列下方的电路密度。接下来是SK Hynix 3D-NAND,它使用折叠结构。

如果我们仔细观察,我们可以看到堆栈从36 - 48 - 72层的演变。36L设备只有一个通门,而48L和72L设备有两个通门,允许两个单元链使用共同的位线和源线。72L堆栈的中心图像有点混乱,因为它有两个正交的图像粘在一起——右边是平行于位线的部分,左边垂直于位线。如果我们看分离的图像,在PG区域的孔表明,左侧部分是通过两个管道门的较低部分,在顶部可以看到单独的位线。
上堆叠是指82栅极堆叠的两级结构。在这次谈话中,河东没有进入这一点的细节,但他发布了一个电子时报博客这澄清了沟道孔是由两步蚀刻过程形成的。估计的过程顺序为:
- 管浇口模具成型(下部)
- 沟道蚀刻(下部42门)
- 牺牲层填充孔
- 模具成型(上部)
- 通道蚀刻(上部,40门)
- 牺牲层去除
- 河道形成
对整个叠片进行一步蚀刻,形成狭缝和子狭缝。在上面的电路原理图中,蓝色的轮廓线显示了顶部和底部堆栈之间的两个虚拟字线的位置,用横截面中的蓝色线标记。

最后讨论的NAND设备是去年在闪存峰会上展示的YMTC 64L部件。这是他们的第二代3D-NAND技术,使用Xtacking将外围电路放在存储阵列的顶部而不是下面。YMTC采用面对面的晶圆键合:

我注释了郑东使用的图像,试图澄清我们正在看的东西:

3D NAND技术创新(今日)
我们在阵列的边缘设置了典型的楼梯,并且他们为每个步骤添加了单词行数,这表明在顶部有一个虚拟的单词行,在单独蒙面的选择门下面。
晶片键合在阵列中共有七个镶嵌金属层,并且在CMOS中有四个,并且在电池堆中总共有74个钨字线。在任何YMTC的声明中没有特别提及,但历史上,他们使用的是使用Chartion-Trap储存的Spansion(现在赛普拉斯)密切合作,因此他们的3D-NAND似乎也是基于充电陷阱的。
该键合很可能是Xperi的DBI®(直接键合互连)技术——上面的TEM图像相当模糊,但它看起来与索尼IMX260堆叠图像传感器的SEM横截面的界面很相似,我们知道它使用了该工艺。

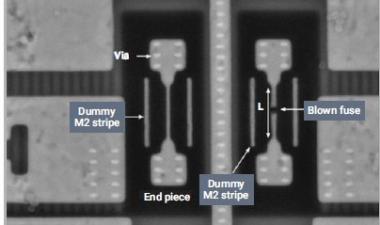
如果我排除了之前详细介绍SSD部件使用包对包(PoP)的幻灯片,那将是我的疏忽,可能不是第一次使用PoP作为内存,但肯定不同于我们习惯在移动电话中看到的通常的apu内存。这是一个三星的单包128gb SSD从微软Surface Pro:

我们在PoP的顶部有两个四层128gb V-NAND芯片,在底部是一个4gb LPDDR4 DRAM和SSD控制器芯片。
Jeongdong以几张总结幻灯片结束了NAND闪存部分,这是迄今为止第一张描述3D NAND创新的幻灯片。这张幻灯片很复杂,所以我就不细说了——有很多创新!除了3D堆栈本身,可能还有一些意想不到的功能,如外延(SEG)晶体管(三星),CuA和双串堆栈(美光),以及管门(SK海力士)。现在我们有了晶圆键合!

总结幻灯片跟踪了到目前为止的进展,并提出了对未来开发的一些担忧。
对我的说明是SK Hynix的返回传统堆栈,没有管门栅极,微米(大概)到四堆叠的弦,以及蚀刻和填充非常高纵横比通道的通用问题。
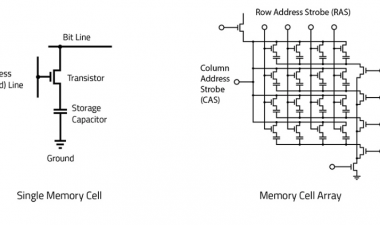
DRAM技术

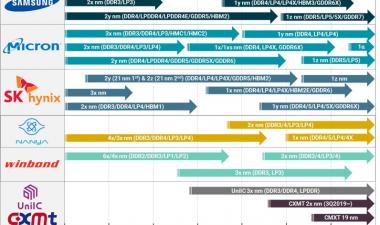
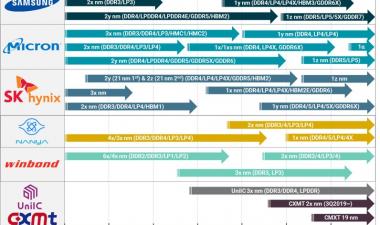
DRAM产品路线图更新
首先,DRAM部分是路线图:
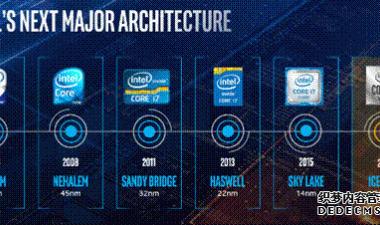
我们现在已经进入了1x纳米的时代,今年还将推出17nm的部件。如果你相信制造商的话,我们还在以一年的节奏推出下一款缩尺,尽管差距更小了,现在我们在20nm以下。几年前,我倾向于认为,在技术达到极限之前,我们可能会有两代的“1-something”节点,但现在看来,我们至少会看到四代,这可能会让我们至少到2025年。

DRAM技术发展趋势
从节点的时间趋势可以看出收缩速率的减慢:

微米1X和1XS纳米DDR4/LPDDR4
在美光被收购之前,尔必达和南亚都处于平稳状态。
Jeongdong还向我们提供了一些美光近期的内存细节,显示在8gb芯片中,它们的位密度现在达到了0.167 Gb/mm2。

AMD & NVIDIA GPU卡概述
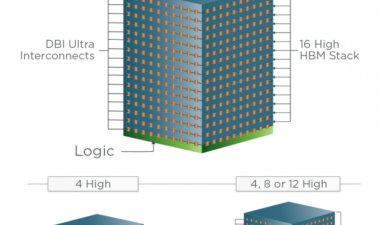
然后看看AMD和Nvidia的gpu,说明使用HBM(高带宽内存)和HBM2的带宽增加,以及从GDDR5X到GDDR6的带宽和速度。

提到HBM让人想起了Micron的HMC(混合内存立方体),它现在已经演变成HMC2。最初的HMC用于Intel Knight's Landing处理器,这是一种四层DRAM,底部带有IBM生产线控制器芯片,通过硅通孔(TSV)连接。HMC2似乎是作为一个独立的产品发布的,但仍然是一个带有控制器的4堆栈,HMC和HMC2都使用30 nm级DRAM。
HBM和HMC都使用TSV,但它们是不同的野兽;HMC有它的控制器芯片,完全封装在PCB基板上,而HBM与硅插入器一起使用。然而,美光已经宣布它将停止HMC,所以即使我们看到了它,它也不会存在太久。

ISP/DRAM/CIS(索尼)Micron 35nm(可能,Elpida fab)
DRAM部分的最后一张幻灯片介绍了索尼和三星为移动电话摄像头使用CMOS图像传感器(CI)和处理器(ISP)堆叠DRAM。在索尼IMX400中,DRAM夹在CI和ISP之间;CIS面对面安装在DRAM上,DRAM与ISP面对面。堆栈中的DRAM允许相机系统以960帧/秒的速度运行,这是一种严重的慢动作能力。IMX400是在索尼Experia XZ手机上推出的,我们发表一篇博客在那个时候。

CIS/ISP/DRAM(三星)三星2y
三星S5K2L3 ISOCELL快速成像仪采用了不同的策略——CIS和ISP采用传统的面对面连接方式,并使用tsv进行电连接,而标准DRAM芯片在ISP上采用微碰撞的面对面连接方式。微凸点将DRAM上的再分布层(RDL)连接到ISP背面的基于铜的RDL,后者将它们路由到tsv,通过ISP基板到达前面的金属。在DRAM芯片旁边还有一个虚拟硅片。
新兴的内存技术

新兴内存批量产品:主要参与者
Jeongdong以一篇关于新兴记忆的评论结束了他的演讲——尽管其中一些记忆是如何“新兴”的还有待讨论,因为有些产品已经存在一段时间了。路线图:

Adesto技术CBRAM更新
例如。Everspin一直在制作各种各样的MRAM,虽然现在,相变内存(PC-RAM)已经在许多公司上进行了多次,并且富士通多年来一直运送其Feram。
第一个例子是Adesto CBRAM(导电桥RAM),详细介绍了他们的第一代和第二代CB存储器之间的变化。

Everspin SST-MRAM 2钕创。
从结构上看,桥接层已经从银/锗硫化物变成了基于碲的多层堆栈,我认为它对温度的敏感性低于银。
然后我们展示256-Mb的Everspin第2代STT-MRAM,采用DDR3格式的垂直- mtj(磁性隧道结)技术。

PCM商用产品:2010 - 2018
作为完成本次讲座的3D Xpoint幻灯片的开场白,我们被提醒PC内存已经存在了一段时间,我们已经从128MB从90nm的进程发展到20nm 16GB:

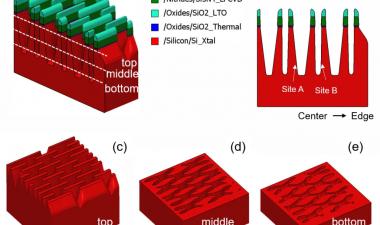
It appears that, at least in the Intel Optane version of 3D Xpoint, there are dummy memory blocks at the memory level (i.e. between metals 4 and 5), which have no drive circuitry, so that the circuit area is different from the memory array area. There are also structural differences in the double stack of the memory cells; in the lower cells it appears that the storage and selector layers are missing (though there are enough shadows of them in this image that the disappearance could be a sample-prep artefact). However, the tungsten wordlines in the centre are clearly separated.

这两层的堆叠当然增加了工艺的复杂性,因为我们必须加倍沉积、蚀刻和照相步骤;在底层,字线位于堆栈顶部,而顶部堆栈的字线位于底部,而位线则相反。
在M4和M5之间添加内存层会给这些层之间的通孔结构带来其他挑战,需要更多的屏蔽层和相关成本。上面的字线和位线实际上是从下面连接的;例如,位线有一个由四个子过孔组成的堆栈,以达到最高位线级别。

洞察与问题:过程/设计观点
在平面图中,它看起来同样复杂,因此这就提出了一个问题——如果我们想使用更多的双层结构,我们该怎么办?(BE/ME/TE=底部/中间/顶部电极。)

洞察与问题:过程/设计观点
目前,双模式正在被使用,但当然有可能发展到四模式,甚至是EUV,可能是多堆栈或3D结构;
演讲结束了,但是不要忘记所有的信息,还有更多的信息,都可以通过TechInsights的内存订阅。